Als je de waarschuwing ‘Geïndexeerd, maar geblokkeerd door robots.txt’ melding hebt ontvangen in Google Search Console, wil je dit zo snel mogelijk oplossen, omdat het de mogelijkheid van je pagina's om te ranken in de zoekresultatenpagina's (SERPS) kan beïnvloeden.
Een robots.txt-bestand is een bestand dat zich in de directory van je website bevindt, dat enkele instructies biedt voor zoekmachinecrawlers, zoals de bot van Google, over welke bestanden ze wel en niet moeten bekijken.
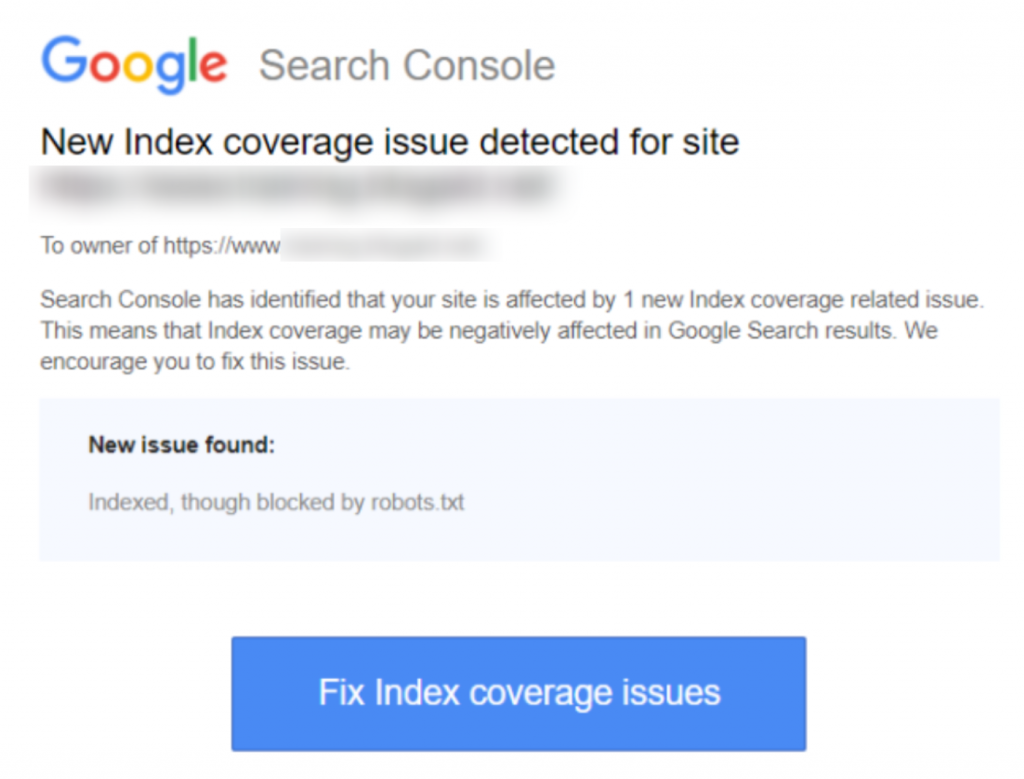
‘Geïndexeerd, maar geblokkeerd door robots.txt’ geeft aan dat Google je pagina heeft gevonden, maar ook een instructie heeft gevonden om deze te negeren in je robots-bestand (wat betekent dat het niet in de resultaten zal verschijnen).
Soms is dit opzettelijk, of soms is het per ongeluk, om een aantal redenen die hieronder worden uiteengezet, en kan worden opgelost.
Hier is een screenshot van de melding:
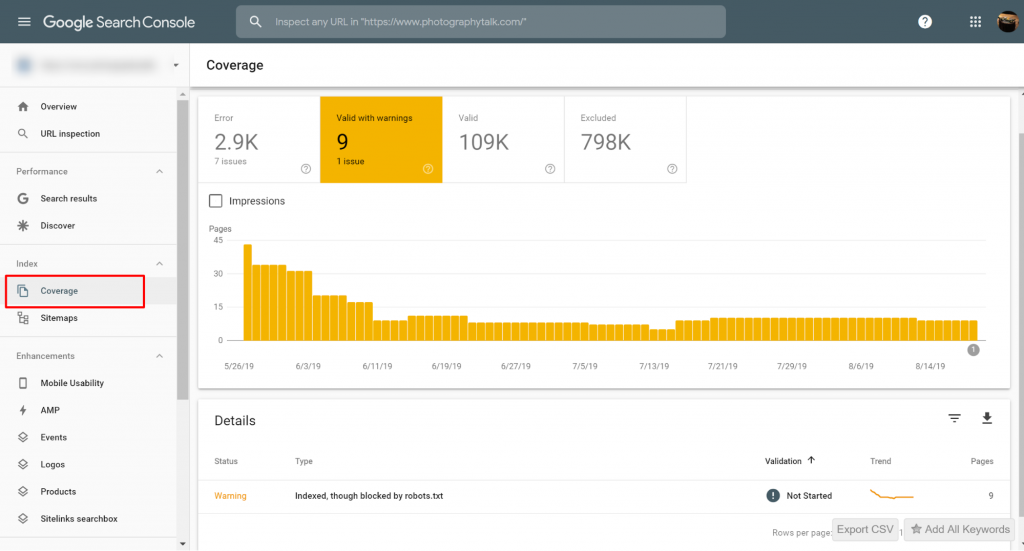
Identificeer de getroffen pagina('s) of URL('s)
Als je een melding hebt ontvangen van Google Search Console (GSC), moet je de specifieke pagina('s) of URL('s) in kwestie identificeren.
Je kunt pagina's bekijken met de Geïndexeerd, hoewel geblokkeerd door robots.txt-problemen op Google Search Console>>Dekking. Als je het waarschuwingslabel niet ziet, dan ben je vrij en duidelijk.
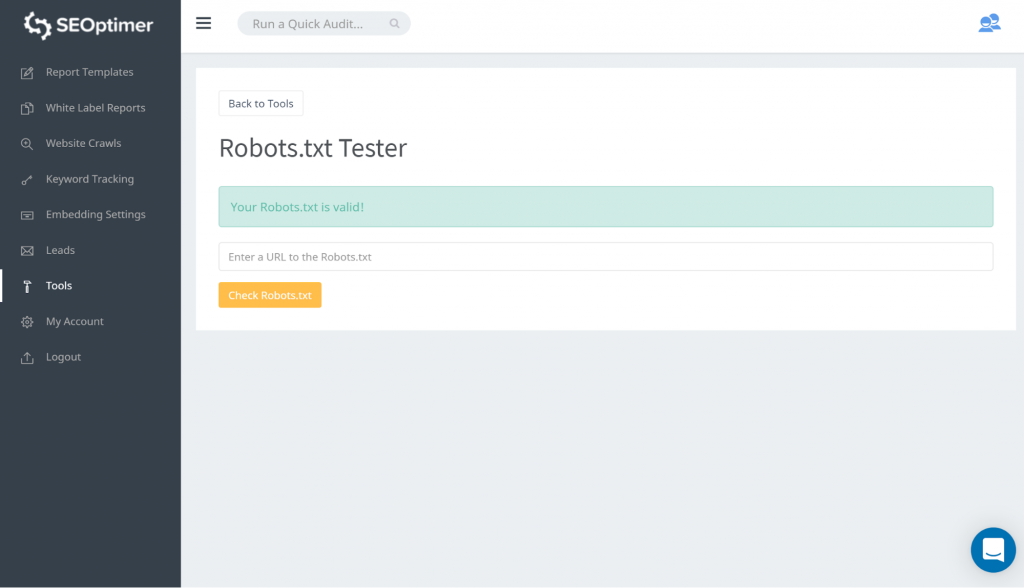
Een manier om je robots.txt te testen is door gebruik te maken van onze robots.txt tester. Je kunt ontdekken dat je het goed vindt dat wat er ook geblokkeerd wordt, ‘geblokkeerd’ blijft. Je hoeft daarom geen actie te ondernemen.
Je kunt ook deze GSC link volgen. Je moet dan:
- Open de lijst van de geblokkeerde bronnen en kies het domein.
- Klik op elke bron. Je zou deze popup moeten zien:
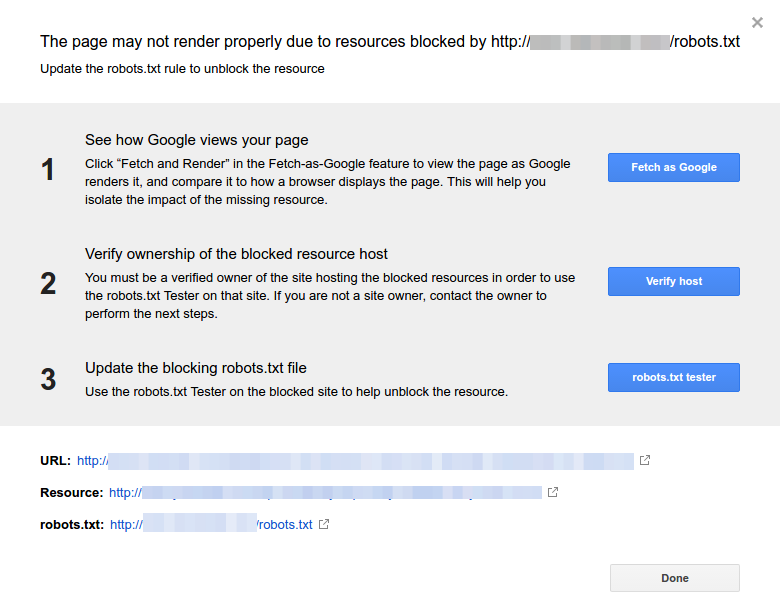
Identificeer de reden voor de melding
De melding kan om verschillende redenen optreden. Hier zijn de meest voorkomende:
Maar eerst, het is niet per se een probleem als er pagina's geblokkeerd zijn door robots.txt., Het kan ontworpen zijn om redenen, zoals, ontwikkelaar die onnodige / categoriepagina's of duplicaten wil blokkeren. Dus, wat zijn de discrepanties?
Verkeerd URL-formaat
Soms kan het probleem voortkomen uit een URL die niet echt een pagina is. Bijvoorbeeld, als de URL https://www.seoptimer.com/nl/?s=digital+marketing, moet je weten naar welke pagina de URL verwijst.
Als het een pagina is met belangrijke inhoud die je echt wilt dat je gebruikers zien, dan moet je de URL wijzigen. Dit is mogelijk op Content Management Systems (CMS) zoals Wordpress waar je een pagina’s slug kunt bewerken.
Als de pagina niet belangrijk is, of met ons /?s=digital+marketing voorbeeld, het is een zoekopdracht van onze blog dan is het niet nodig om de GSC fout te herstellen.
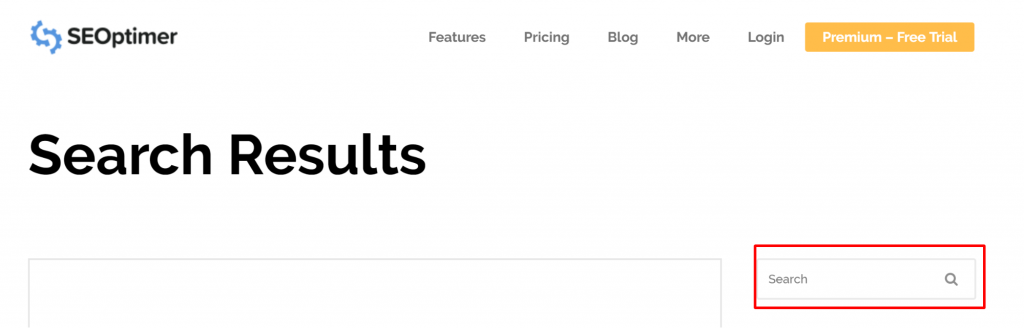
Het maakt geen enkel verschil of het geïndexeerd is of niet, aangezien het niet eens een echte URL is, maar een zoekopdracht. Als alternatief kun je de pagina verwijderen.
Pagina's die geïndexeerd moeten worden
Er zijn verschillende redenen waarom pagina's die geïndexeerd zouden moeten worden, niet geïndexeerd worden. Hier zijn er een paar:
- Heb je je robots-richtlijnen gecontroleerd? Je hebt mogelijk richtlijnen opgenomen in je robots.txt-bestand die het indexeren van pagina's verbieden die eigenlijk geïndexeerd zouden moeten worden, bijvoorbeeld, tags en categorieën. Tags en categorieën zijn daadwerkelijke URL's op je site.
- Wijs je de Googlebot naar een omleidingsketen? Googlebot gaat door elke link die ze tegenkomen en doen hun best om te lezen voor indexering. Echter, als je een meerdere, lange, diepe omleiding instelt, of als de pagina gewoon onbereikbaar is, zou Googlebot stoppen met kijken.
- De canonical link correct geïmplementeerd? Een canonical tag wordt gebruikt in de HTML-header om Googlebot te vertellen welke de voorkeurs- en canonical pagina is in het geval van gedupliceerde inhoud. Elke pagina moet een canonical tag hebben. Bijvoorbeeld, je hebt een pagina die is vertaald naar het Spaans. Je zult de Spaanse URL zelf canonical maken en je wilt de pagina canonical terug naar je standaard Engelse versie.
Hoe te verifiëren of je Robots.txt correct is op WordPress?
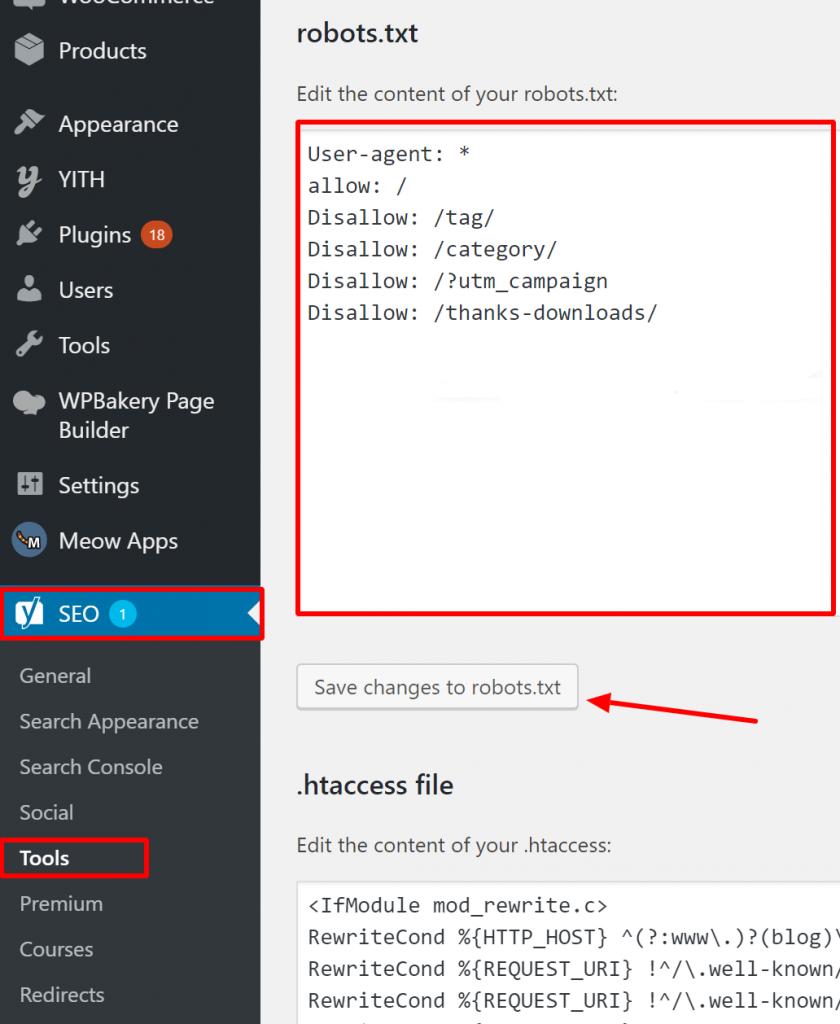
Voor WordPress, als je robots.txt-bestand deel uitmaakt van de site-installatie, gebruik de Yoast Plugin om het te bewerken. Als het robots.txt-bestand dat problemen veroorzaakt op een andere site staat die niet van jou is, moet je communiceren met de site-eigenaren en hen vragen hun robots.txt-bestand te bewerken.
Pagina's die niet geïndexeerd moeten worden
Er zijn verschillende redenen waarom pagina's die niet geïndexeerd zouden moeten worden, toch geïndexeerd worden. Hier zijn er een paar:
Robots.txt-richtlijnen die ‘zeggen’ dat een pagina niet geïndexeerd mag worden. Let op dat je de pagina met een ‘noindex’-richtlijn moet toestaan om gecrawld te worden zodat de zoekmachinebots ‘weten’ dat deze niet geïndexeerd mag worden.
Zorg ervoor dat in je robots.txt-bestand:
- De ‘disallow’ regel volgt niet direct op de ‘user-agent’ regel.
- Er is niet meer dan één ‘user-agent’ blok.
- Onzichtbare Unicode-tekens - je moet je robots.txt-bestand door een teksteditor halen die coderingen omzet. Dit zal alle speciale tekens verwijderen.
Pagina's zijn gelinkt vanaf andere sites. Pagina's kunnen geïndexeerd worden als ze gelinkt zijn vanaf andere sites, zelfs als dit niet is toegestaan in robots.txt. In dit geval verschijnen echter alleen de URL en ankertekst in zoekmachineresultaten. Dit is hoe deze URL's worden weergegeven op de zoekmachineresultatenpagina (SERP):
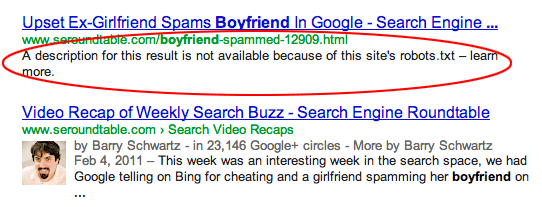
afbeelding bron Webmasters StackExchange
Een manier om het robots.txt-blokkeringsprobleem op te lossen, is door het bestand/de bestanden op uw server met een wachtwoord te beveiligen.
Als alternatief, verwijder de pagina's uit robots.txt of gebruik de volgende meta tag om te blokkeren
hen:
<meta name=”robots” content=”noindex”>
Oude URL's
Als je nieuwe inhoud of een nieuwe site hebt gemaakt en een ‘noindex’ directive in robots.txt hebt gebruikt om ervoor te zorgen dat deze niet wordt geïndexeerd, of je hebt je onlangs aangemeld voor GSC, zijn er twee opties om het probleem geblokkeerd door robots.txt op te lossen:
- Geef Google de tijd om uiteindelijk de oude URL's uit zijn index te verwijderen
- 301 redirect de oude URL's naar de huidige
In het eerste geval verwijdert Google uiteindelijk URL's uit zijn index als ze alleen maar 404's retourneren (wat betekent dat de pagina's niet bestaan). Het is niet raadzaam om plugins te gebruiken om je 404's te omleiden. De plugins kunnen problemen veroorzaken die ertoe kunnen leiden dat GSC je de ‘geblokkeerd door robots.txt’ waarschuwing stuurt.
Virtuele robots.txt-bestanden
Er is een mogelijkheid om een melding te krijgen, zelfs als je geen robots.txt-bestand hebt. Dit komt omdat CMS (Customer Management Systems) gebaseerde sites, bijvoorbeeld WordPress, virtuele robots.txt-bestanden hebben. Plug-ins kunnen ook robots.txt-bestanden bevatten. Deze zouden de problemen op je site kunnen veroorzaken.
Deze virtuele robots.txt moeten worden overschreven door je eigen robots.txt-bestand. Zorg ervoor dat je robots.txt een richtlijn bevat om alle zoekmachinebots toe te staan je site te crawlen. Dit is de enige manier waarop ze kunnen bepalen welke URL's geïndexeerd moeten worden of niet.
Hier is de richtlijn die alle bots toestaat om je site te crawlen:
User-agent: *
Niet toestaan: /
Het betekent ‘niets verbieden’.
Concluderend
We hebben gekeken naar de ‘Indexed, though blocked by robots.txt warning’, wat het betekent, hoe de getroffen pagina's of URL's te identificeren, evenals de reden achter de waarschuwing. We hebben ook gekeken naar hoe het te verhelpen. Merk op dat de waarschuwing niet gelijk staat aan een fout op je site. Het niet oplossen ervan kan echter resulteren in het niet indexeren van je belangrijkste pagina's, wat niet goed is voor de gebruikerservaring.